A machine learning pipeline is an organised, automated process that converts raw data into reliable and easily deployable AI models. With the world of artificial intelligence upon us, it’s crucial to understand this concept, whether you’re an aspiring data scientist, a business leader trying to build effective machine learning models, or a data visualisation enthusiast.
Understanding the Basics
Essentially, a machine learning pipeline is like an efficient assembly line. Rather than executing each step manually — which can be tedious, error-prone, and difficult to reproduce — it links together a chain of automated processes. This orchestration provides consistency, scalability, and faster iteration from raw data to final predictions in production environments.
Consider it the scaffolding of modern machine learning projects. Without a proper, well-devised pipeline, even the most skilled algorithms know the risks of failing when going from trials to real-world production.
Key Stages of a Machine Learning Pipeline
A typical machine learning pipeline flows through several interconnected stages. Here’s a clear breakdown:
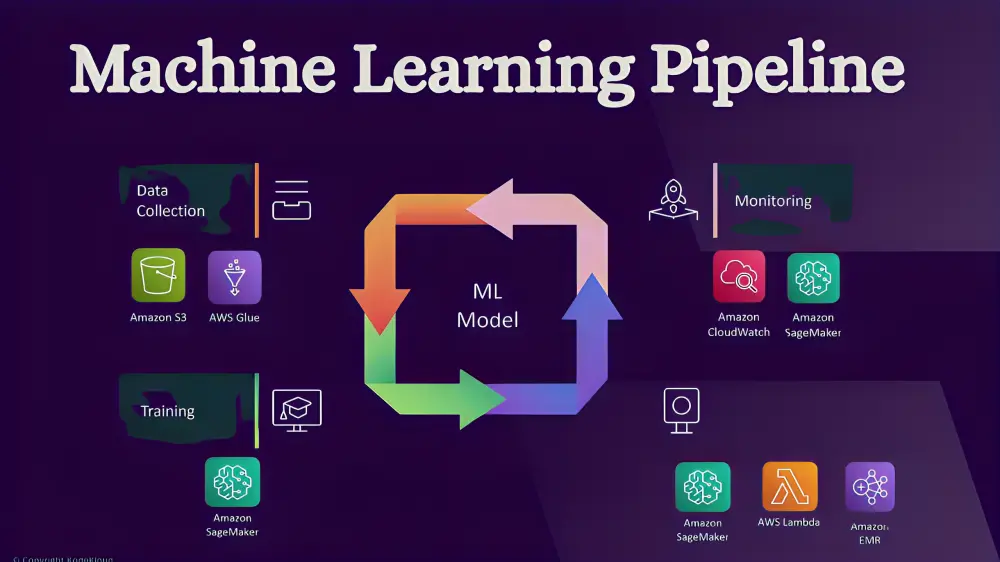
1. Data Collection and Ingestion
It all begins with collecting data from various sources — databases, APIs, sensors, logs, or streaming platforms. This stage is all about efficiently ingesting raw, unstructured data while ensuring it adheres to quality and compliance standards.
2. Data Preprocessing and Cleaning
Raw data is often messy. The pipeline cleans (removing duplicates or errors), normalises, deals with missing values, and performs exploratory analysis here. The objective is to ensure that models learn from high-quality data.
3. Feature Engineering
Feature engineering is a creative yet critical step in data preparation, as it consists of transforming raw data into features that enhance model performance. These techniques could vary from scaling and encoding categorical variables to creating new variables or simply a basket of knowledge.
4. Model Training and Selection
The prepared data will go into the machine learning algorithms. The pipeline can train many models, tune hyperparameters (often automatically via AutoML), and leave the best-performing one selected based on a metric: accuracy, precision, F1-score, etc.
5. Model Evaluation and Validation
The model is subjected to heavy testing with unseen data before deployment. Methods such as cross-validation promote good model generalisation and prevent overfitting.
6. Deployment and Serving
Once validated, the model is put into production. It can be integrated with applications, APIs, or edge devices for making predictions in real-time. Some modern pipelines also help you run A/B tests, which let you roll out your changes safely.
7. Monitoring, Maintenance, and Retraining
Post-deployment isn’t the end—it’s ongoing. It also monitors the pipeline for data drift and model performance degradation automatically when needed. This is called closed-loop feedback and makes the system adaptive.
Many pipelines in 2026 will also bring advanced elements like multimodal data handling, explainability tools, and governance for responsible AI.
Why Do Machine Learning Pipelines Matter?
Modelling without a pipeline is like cooking without a recipe — doable, but prone to everything from inconsistency and inefficiency. Well-designed pipelines offer major advantages:
- Automation and Efficiency — Repetitive tasks run automatically, saving time and reducing human error.
- Reproducibility — The same results can be achieved across teams and environments.
- Scalability — Handle massive datasets and growing model complexity with ease.
- Collaboration — Data engineers, scientists, and DevOps teams work seamlessly together.
- Faster Time-to-Value — Move from idea to production much quicker.
With the rise of MLOps (Machine Learning Operations), pipelines have started to handle machine learning as a software engineering task—think of using version control for data/code/models and CI/CD practices.
Popular Tools and Technologies in 2026
Powerful frameworks have never made it easier to implement a machine learning pipeline:
- MLflow: Excellent for experiment tracking, model versioning, and deployment.
- Kubeflow: Ideal for orchestrating scalable pipelines on Kubernetes.
- TensorFlow Extended (TFX) or Google Vertex AI Pipelines: For end-to-end production workflows.
- Cloud platforms like AWS SageMaker, Azure Machine Learning, and Databricks offer managed solutions with built-in automation.
- Trends on the rise include hyperautomation as generative AI is leveraged to help design and build your pipelines and a renewed focus on LLMOps, also for processing large language models, as well as governance and ethical AI.
Best Practices for Success
To build an effective machine learning pipeline:
- Start modular and reusable: design components that can be swapped or scaled independently.
- Incorporate version control for everything (data, code, models).
- Automate testing and monitoring from day one.
- Prioritise scalability and cost-efficiency, especially with cloud resources.
- Focus on explainability and compliance for regulated industries.
Summary
In essence, a machine learning pipeline is a well-structured, automated process that transforms raw data into powerful AI solutions. It is empowering organisations with confidence to build reliable and scalable machine learning systems by streamlining the data handling, model development, deployment, and ongoing maintenance. Mastering pipelines is the doorway to unleashing the full capabilities of AI, whether you are just getting started or optimising enterprise workflows. As the tech landscape evolves through 2026 and beyond, building and investing in no-nonsense machine learning pipelines will set apart successful AI initiatives from others—pushing innovation forward, improving efficiency, and generating true business value. Are you ready to create your first one? This is the beginning of the future for intelligent systems.
FAQ’s
Q1. What are the 5 models of machine learning?
Ans. There are various types, but the five primary machine learning models include supervised (learning with labelled data), unsupervised (detecting patterns in unlabelled data), semi-supervised (a combination of both), reinforcement (learning through trial & reward), and deep learning neural networks for intricate tasks.
Q2. Is ChatGPT AI or ML?
Ans. ChatGPT is both AI and ML. It is an artificial intelligence (AI) programme constructed using machine learning (ML) methods using deep learning on very large datasets. ML is the approach; AI denotes intelligent behaviour itself. To sum it up, ChatGPT is an example of AI powered by ML.
Q3. What are the 4 pillars of machine learning?
Ans. “Four Pillars” of Machine Learning: Data, Algorithms, Computation, and Evaluation. Data is simply the fuel that powers these models, as it provides them with the necessary information to function properly. The algorithms are the methods that search, find, and learn from this data. Computation provides the necessary hardware to facilitate training promptly. Lastly, evaluation serves to measure performance and then feed into a process of continuous improvement, making up the full foundation for building trustworthy machine learning systems.





